vue3 数据响应式原理分析
2021年4月28日 · 预计阅读时间: 16 分钟
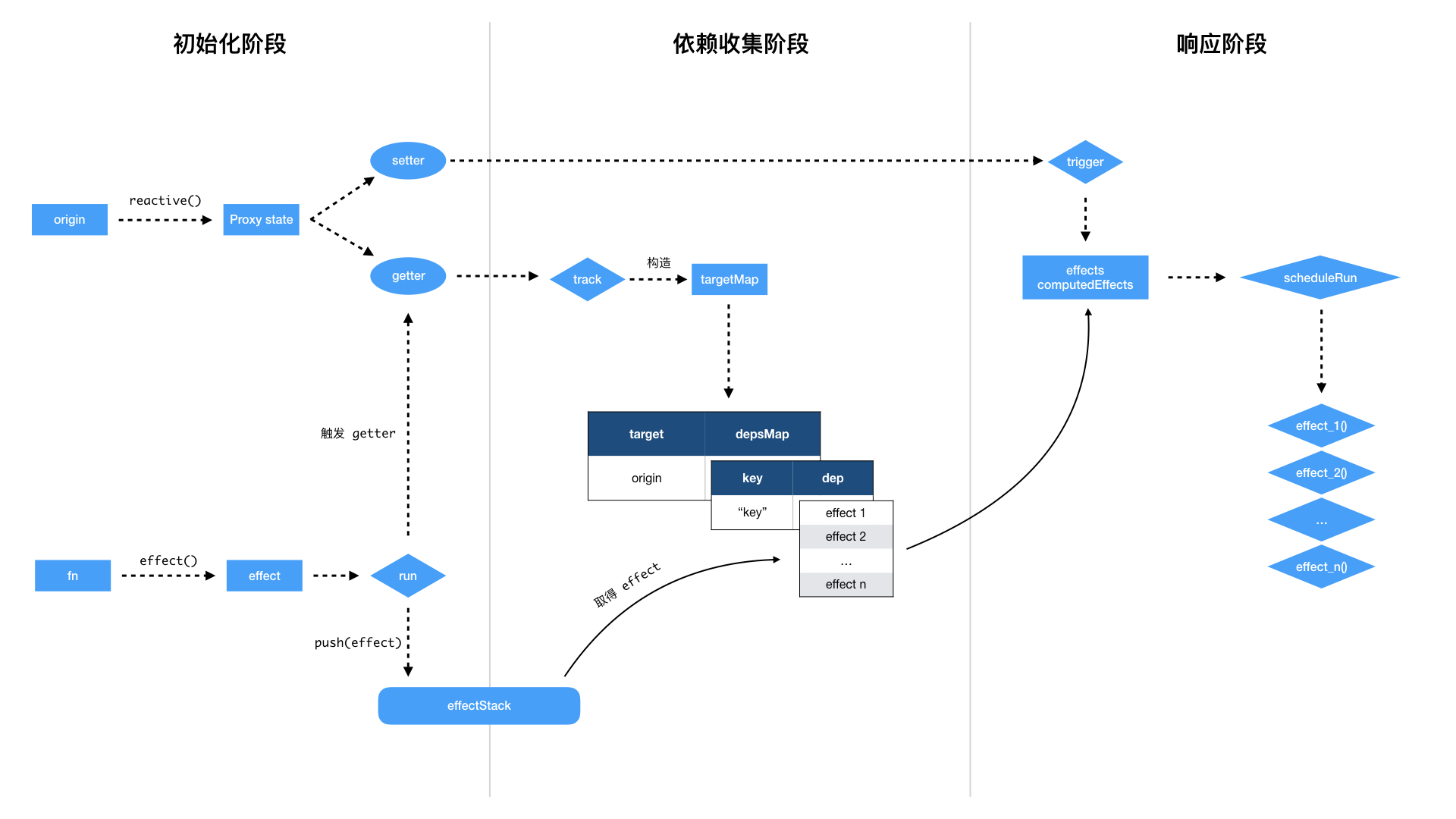
按响应流程和简化版源码来分析响应式系统
reactivity
vue3 中的 reactivity 是一个独立的包,可以完全脱离 vue 使用,理论上在任何地方都可以使用 (react 都可以)
我们先来看看 reactivity 包的使用
在项目根目录运行
yarn dev reactivity,然后进入packages/reactivity目录找到产出的dist/reactivity.global.js文件。新建一个
index.html,写入如下代码:<script src="./dist/reactivity.global.js"></script>
<script>
const { reactive, effect } = VueObserver
const origin = {
count: 0,
}
const state = reactive(origin)
const fn = () => {
const count = state.count
console.log(`set count to ${count}`)
}
effect(fn)
</script>在浏览器打开该文件,于控制台执行
state.count++,便可看到输出set count to 1。
在上述的例子中,我们使用 reactive() 函数把 origin 对象转化成了 Proxy 对象 state;使用 effect() 函数把 fn() 作为响应式回调。当 state.count 发生变化时,便触发了 fn()。接下来我们将结合上文的流程图,用简化版的源码,来讲解这套响应式系统是怎么运行的。
初始化阶段
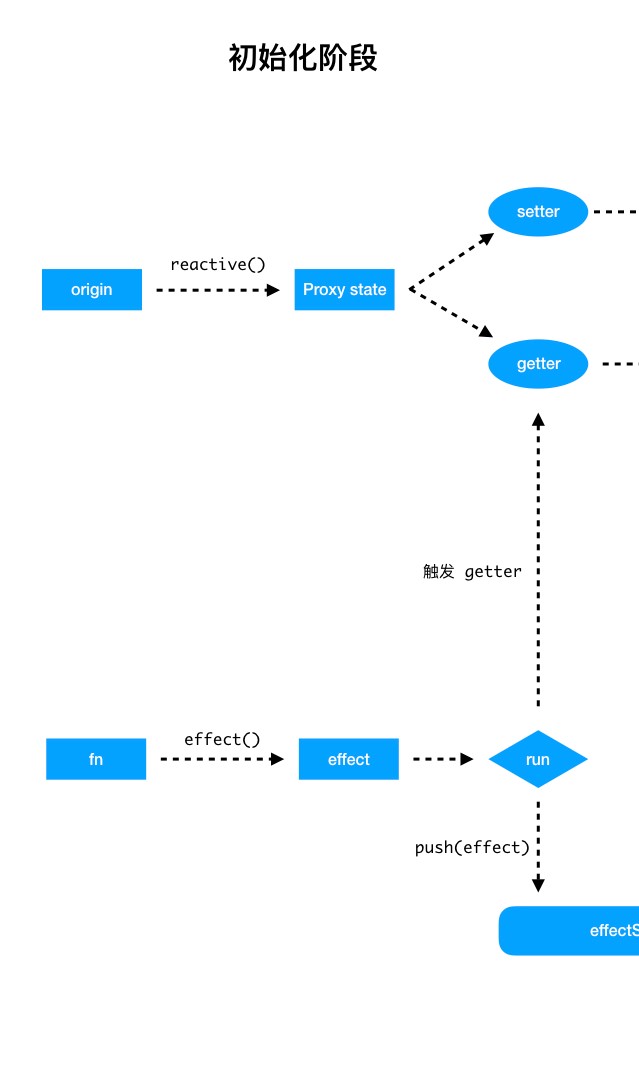
在初始化阶段,主要做了两件事:
- 把
origin对象转化成响应式的 Proxy 对象state。 - 把函数
fn()作为一个响应式的 effect 函数。
首先我们来分析第一件事。
vue3 使用了Proxy代理对象,改写了对象的setter和getter操作,来实现依赖收集和响应触发。在初始化阶段,我们先不详细说setter和getter的实现,先来看看reactive函数到底干了什么。
export function reactive<T extends object>(target: T) {
return createReactiveObject(target, handler)
}
export function createReactiveObject(
target: object,
handler: ProxyHandler<any>
) {
const observed = new Proxy(target, handler)
return observed
}
可以看到reactive函数仅仅是将我们传入的对象用Proxy代理,并传入了handler。
让我们再来看看第二件事
当一个普通的函数 fn() 被 effect() 包裹之后,就会变成一个响应式的 effect 函数,而 fn() 也会被立即执行一次(设置为 lazy 的话不执行),fn执行之后,如果有用到Proxy的对象,那么就会触发getter收集依赖。
这个effect也会被压入effectStack栈中,供后续调用。
const effectStack: ReactiveEffect[] = []
let activeEffect: ReactiveEffect | undefined
export function effect<T = any>(fn: () => T) {
const effect = createReactiveEffect(fn)
effect() // 立即执行一次
return effect
}
function createReactiveEffect<T = any>(fn: () => T): ReactiveEffect<T> {
const effect = function reactiveEffect(): unknown {
if (!effectStack.includes(effect)) {
cleanup(effect) // 防止 fn() 中含有 if 等条件判断语句导致依赖不同。所以每次执行函数时,都要重新更新一次依赖。
try {
effectStack.push(effect) // 将本 effect 推到 effect 栈中
activeEffect = effect
// 立即执行一遍 fn()
// fn() 执行过程会完成依赖收集,会用到 track
return fn()
} finally {
// 执行完以后将 effect 从栈中推出
effectStack.pop()
activeEffect = effectStack[effectStack.length - 1]
}
}
} as ReactiveEffect
effect.deps = [] // 收集对应的 dep,cleanup 时以找到 dep,从 dep 中清除 effect
return effect
}
这里还有几个小问题:
既然执行前
effectStack.push(effect),执行后effectStack.pop()。那为什么还要判断effectStack.includes(effect)这种情况呢?其实是解决在
fn()中改变state的问题,比如effect(() => state.num++)按正常逻辑是会不断的触发监听函数的,但通过
effectStack.includes(effect)这么一个判断逻辑,自然而然就避免了递归循环。在
tigger函数中也有一个这样的判断if (effect !== activeEffect) {
effects.add(effect)
}不会触发正在收集的依赖,防止循环调用。
为什么在收集依赖之前需要清除上一轮的依赖
这样做是为了处理带有分支处理的情况。因为监听函数中,可能会由于 if 等条件判断语句导致的依赖数据不同。所以每次执行函数时,都要重新更新一次依赖。所以才有了
cleanup这个逻辑。
依赖收集阶段
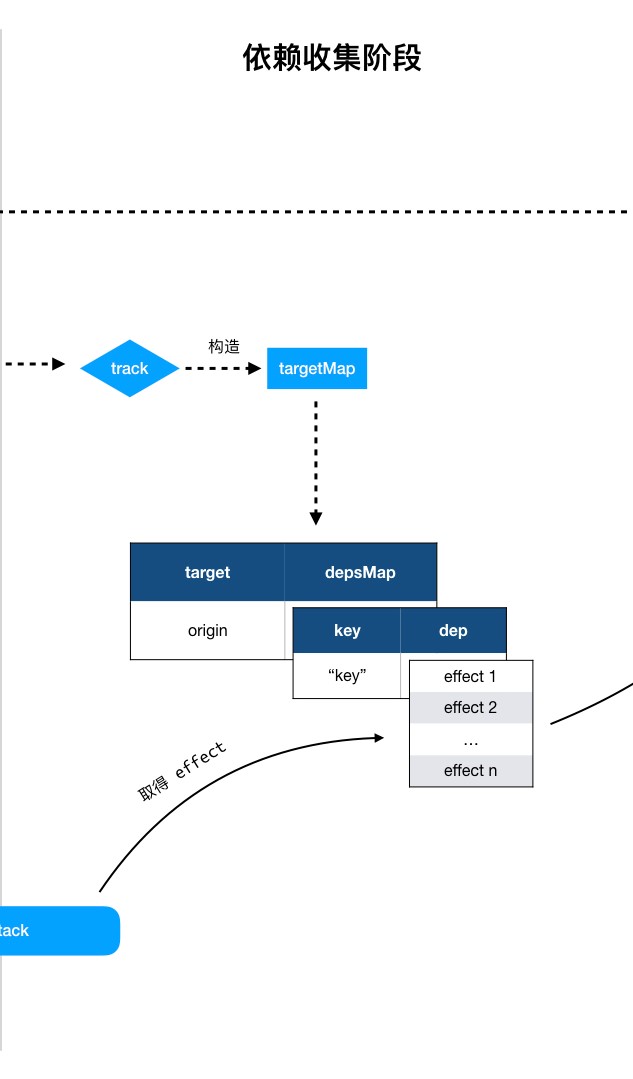
这个阶段的触发时机,就是在 effect 被执行,其内部的 fn() 触发了 Proxy 对象的 getter 的时候。简单来说,只要执行到类似 state.count 的语句,就会触发 state 的 getter。
const get = createGetter()
export const handler = {
get,
}
function createGetter() {
return function get(
target: object,
key: string | symbol,
receiver: object
): any {
const res = Reflect.get(target, key, receiver)
// 如果是 js 的内置方法,不做依赖收集
if (isSymbol(key) && builtInSymbols.has(key)) {
return res
}
track(target, TrackOpTypes.GET, key)
return isObject(res) ? reactive(res) : res
}
}
我们看到 getter 里面调用了track函数进行依赖收集,track具体怎么工作的我们之后再说。
我们先来解释一个问题,为什么内置方法不做依赖收集?
比如一个监听函数是这样
const origin = {
a() {},
}
const observed = reactive(origin)
effect(() => {
console.log(observed.a.toString())
})
很明显,当origin.a 变化时,observed.a.toString()也是应该会变的,那为什么不用监听了呢?很简单,因为已经走到了observed.a.toString()已经触发了getter,没必要重复收集依赖。故而类似的内置方法,直接 return。
还有一个小细节是当访问的属性还是一个对象的时候,我们会调用reactive函数,因为Proxy只能劫持一层,所以有嵌套的对象时,是劫持不了嵌套的对象的,所以源码中使用了 lazy 的方式,如果触发getter的 res 是一个对象,再调用reactive,实现深层响应式,这样还可以避免循环引用。
在收集依赖阶段,我们需要收集一张 “依赖收集表”,也就是图上的targetMap,key 为Proxy代理后的对象,value 为该对象对应的depsMap。
depsMap 是一个 Map,key 值为触发 getter 时的属性值(此处为 count),而 value 则是触发过该属性值所对应的各个 effect。
targetMap的定义如下:
type Dep = Set<ReactiveEffect>
type KeyToDepMap = Map<any, Dep>
const targetMap = new WeakMap<any, KeyToDepMap>()
举个栗子:
const state = reactive({
count: 0,
age: 18,
})
const effect1 = effect(() => {
console.log('effect1: ' + state.count)
})
const effect2 = effect(() => {
console.log('effect2: ' + state.age)
})
const effect3 = effect(() => {
console.log('effect3: ' + state.count, state.age)
})
这里的 targetMap 应该就是这样:

这样,{ target -> key -> dep } 的对应关系就建立起来了,依赖收集也就完成了。
我们来看看track是怎么实现的,
export function track(
target: object,
type: TrackOpTypes,
key: string | symbol
) {
if (activeEffect === undefined) {
return
}
let depsMap = targetMap.get(target)
if (!depsMap) {
targetMap.set(target, (depsMap = new Map()))
}
let dep = depsMap.get(key)
if (!dep) {
depsMap.set(key, (dep = new Set()))
}
if (!dep.has(activeEffect)) {
// 将 activeEffect add 到集合 dep 中,供 trigger 调用
dep.add(activeEffect)
// 并在 effect 的 deps 中也 push 这个 effects 集合 dep 供 cleanup 清除上一轮的依赖,防止本轮触发多余的依赖
activeEffect.deps.push(dep)
}
}
targetMap的depsMap中存了effect的集合dep,而effect中又存了这个dep...乍看有点儿懵,而且为什么要双向存?
其实我们已经知道了原因,就是cleanup,effect 通过cleanup,在自己被执行前,把自己从响应依赖映射中删除了。然后执行自身原始函数fn,然后触发数据的get,然后触发track,然后又会把本effect添加到相应的Set中。每次执行前,把自己从依赖映射中删除,执行过程中,又把自己加回去。保证每次的依赖都是最新的。
响应阶段
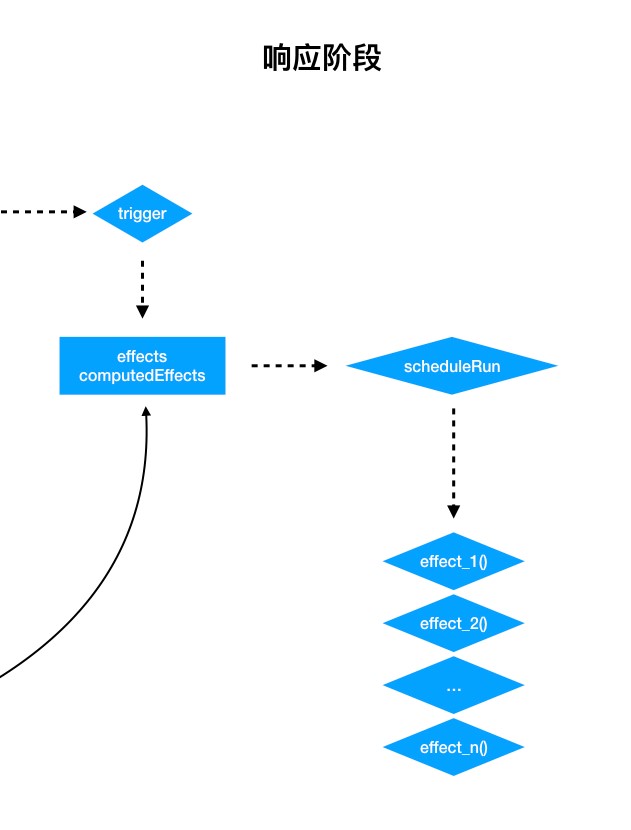
当修改对象的某个属性值的时候,会触发对应的 setter。
const set = createSetter()
export const handler = {
set,
}
function createSetter() {
return function set(
target: object,
key: string | symbol,
value: unknown,
receiver: object
): boolean {
const hadKey = hasOwn(target, key)
const oldValue = (target as any)[key]
// 这里一定要先执行 set 后再 trigger,effect 中可能有操作依赖于 set 后的对象,先 set 能保证 effect 中的函数执行出正确的结果
const result = Reflect.set(target, key, value, receiver)
if (!hadKey) {
trigger(target, TriggerOpTypes.ADD, key)
} else if (value !== oldValue) {
trigger(target, TriggerOpTypes.SET, key)
}
return result
}
}
setter 里面的 trigger() 函数会从依赖收集表里找到当前属性对应的各个 dep,然后把它们推入到 effects 中,最后通过 scheduleRun() 挨个执行里面的 effect。
export function trigger(target: object, type: TriggerOpTypes, key?: unknown) {
const depsMap = targetMap.get(target)
if (!depsMap) {
return
}
// 需要新建一个 set,如果直接 const effect = depsMap.get(key)
// effect 函数执行时 track 的依赖就也会在这一轮 trigger 执行,导致无限循环
const effects = new Set<ReactiveEffect>()
const add = (effectsToAdd: Set<ReactiveEffect> | undefined) => {
if (effectsToAdd) {
effectsToAdd.forEach(effect => {
// 不要添加自己当前的 effect,否则遇到 effect(() => foo.value++) 会导致无限循环
if (effect !== activeEffect) {
effects.add(effect)
}
})
}
}
// SET | ADD
if (key !== undefined) {
// 添加 key 对应的 effect
add(depsMap.get(key))
}
// iteration key on ADD
switch (type) {
case TriggerOpTypes.ADD:
// 增加数组元素会改变数组长度
if (isArray(target) && isIntegerKey(key)) add(depsMap.get('length'))
}
// 简化版 scheduleRun,挨个执行 effect
effects.forEach(effect => {
effect()
})
}
小细节
避免多次 tigger
当代理对象是数组时,push 操作会触发多次 set 执行,同时,也引发 get 操作
let data = [1, 2, 3]
let p = new Proxy(data, {
get(target, key, receiver) {
console.log('get value:', key)
return Reflect.get(target, key, receiver)
},
set(target, key, value, receiver) {
console.log('set value:', key, value)
return Reflect.set(target, key, value, receiver)
},
})
p.unshift('a')
// get value: unshift
// get value: length
// get value: 2
// set value: 3 3
// get value: 1
// set value: 2 2
// get value: 0
// set value: 1 1
// set value: 0 a
// set value: length 4
可以看到,在对数组做 unshift 操作时,会多次触发 get 和 set 。 仔细观察输出,不难看出,get 先拿数组最末位下标,开辟新的下标 3 存放原有的末位数值,然后再将原数值都往后挪,将 0 下标设置为了 unshift 的值 a ,由此引发了多次 set 操作。
而这对于 通知外部操作 显然是不利,我们假设 set 中的 console 是触发外界渲染的 render 函数,那么这个 unshift 操作会引发 多次 render 。
我们来看看 vue3 是怎么解决这个问题的
export const hasOwn = (
val: object,
key: string | symbol
): key is keyof typeof val => Object.prototype.hasOwnProperty.call(val, key)
function createSetter() {
return function set(
target: object,
key: string | symbol,
value: unknown,
receiver: object
): boolean {
console.log(target, key, value)
const hadKey = hasOwn(target, key)
const oldValue = (target as any)[key]
const result = Reflect.set(target, key, value, receiver)
if (!hadKey) {
console.log('trigger ... is a add OperationType')
trigger(target, TriggerOpTypes.ADD, key)
} else if (value !== oldValue) {
console.log('trigger ... is a set OperationType')
trigger(target, TriggerOpTypes.SET, key)
}
return result
}
}
当改变数组长度的时候
const state = reactive([1])
state.push(1)
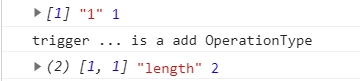
state.push(1)触发了两次 set,一次是值本身1,一次是length属性改变。
当我们设置值本身的时候是一个 add 操作,hasOwn(target, key)显然返回 false,
而 length 是一个自身属性,hasOwn(target, key)返回true,且oldvalue === value,所以没有触发 trigger。
所以通过 判断 key 是否为 target 自身属性,以及设置 val 是否跟 target[key] 相等 可以确定 trigger 的类型,并且避免多余的 trigger。
深度响应式
还有一个细节就是,Proxy只能代理一层,比如
let data = { foo: 'foo', bar: { key: 1 }, ary: ['a', 'b'] }
let p = new Proxy(data, {
get(target, key, receiver) {
console.log('get value:', key)
return Reflect.get(target, key, receiver)
},
set(target, key, value, receiver) {
console.log('set value:', key, value)
return Reflect.set(target, key, value, receiver)
},
})
p.bar.key = 2
// get value: bar
执行代码,可以看到并没有触发 set 的输出,反而是触发了 get ,因为 set 的过程中访问了 bar 这个属性。 由此可见,proxy 代理的对象只能代理到第一层,而对象内部的深度侦测,是需要开发者自己实现的。同样的,对于对象内部的数组也是一样。
p.ary.push('c')
// get value: ary
所以在 vue3 使用了 lazy 的方式来实现深度响应式
function createGetter() {
return function get(
target: object,
key: string | symbol,
receiver: object
): any {
const res = Reflect.get(target, key, receiver)
track(target, TrackOpTypes.GET, key)
return isObject(res) ? reactive(res) : res
}
}
判断了res是否是一个对象,是对象的话就再走一遍reactive,并且会将这个对象存入reactiveMap中,提高性能。
// 已经有了对应的 proxy
const existingProxy = reactiveMap.get(target)
if (existingProxy) {
return existingProxy
}